Credit Risk Modelling

Disclaimer: The Process and the Charts are to be used carefully, as they change a lot based on the loan product type, customer cohort and other loan parameters. Here we have just presented a very generic overview of a vanilla product. All the data used for the credit risk modelling is with Roopya.
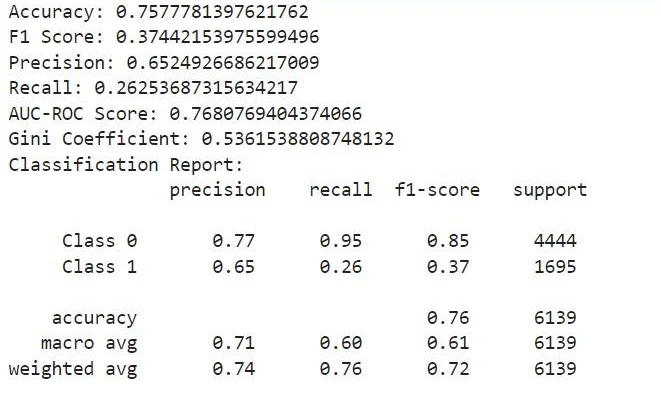
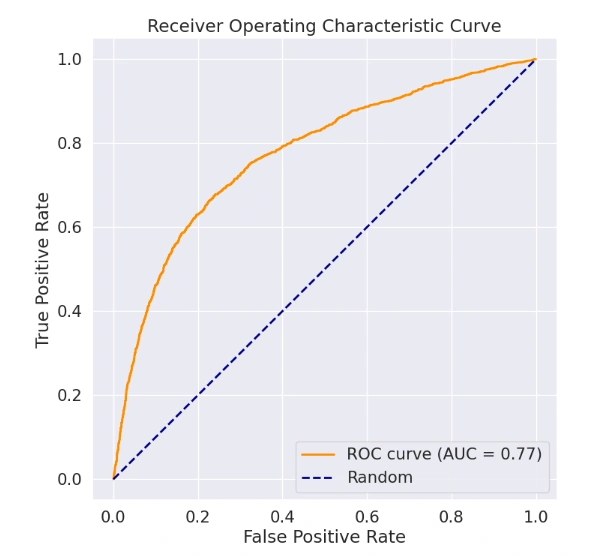
We explore the models created for the Roopya Score which aims to determine whether a customer’s creditworthiness is ‘Good’ or ‘Bad’ based on various input factors. We use various statistical methods used in credit scoring and provide an in-depth look at how the model was developed, including important considerations in the process. We also apply quantitative criteria to find the best model, highlighting its key qualities as an effective scorecard.
Start Free Trial
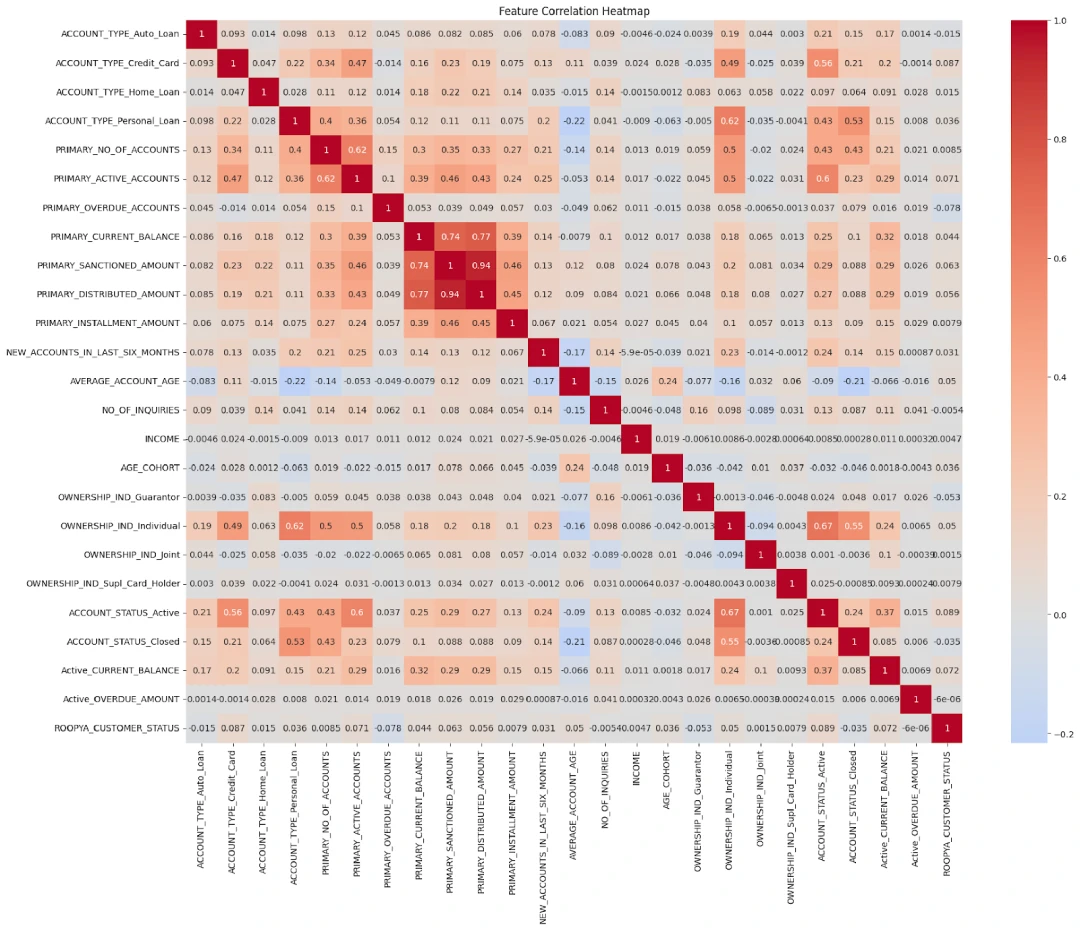
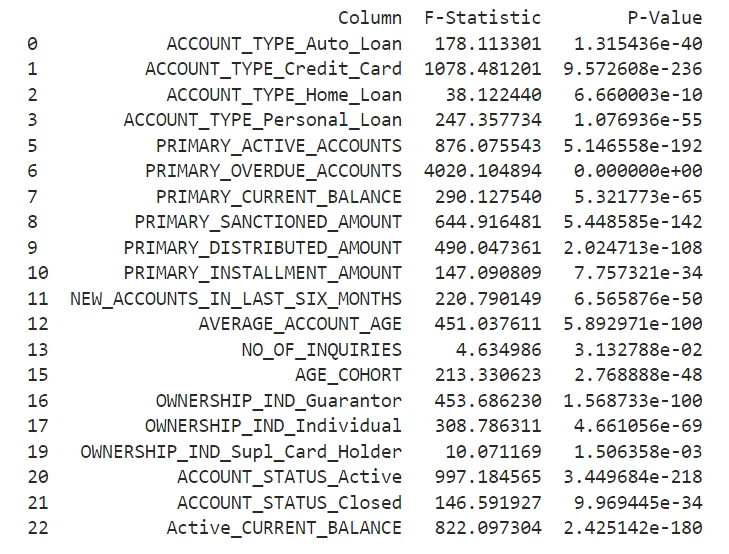
Using data from loan applications, we guide you through essential steps, including data preparation, selecting important features, converting variables using the Weight of Evidence (WOE) method, building the logistic regression model, conducting thorough evaluations, and ultimately creating a credit scoring system.
A credit score is a numerical representation of a customer’s creditworthiness. There are two main categories of credit scoring models: application scoring and behavioural scoring. Application scoring is used to evaluate the risk of default when a customer applies for credit, using data like demographic information and credit bureau records. Behavioural scoring, on the other hand, assesses the risk associated with existing customers. This is done by examining their recent account transactions, current financial data, repayment history, any delinquencies, credit bureau information, and their overall relationship with the bank. Identifying high-risk clients enables the bank to take proactive measures to protect itself from potential future losses.